Audio Coding & Generative Model
Generative De-Quantization for Neural Speech Codec via Latent Diffusion
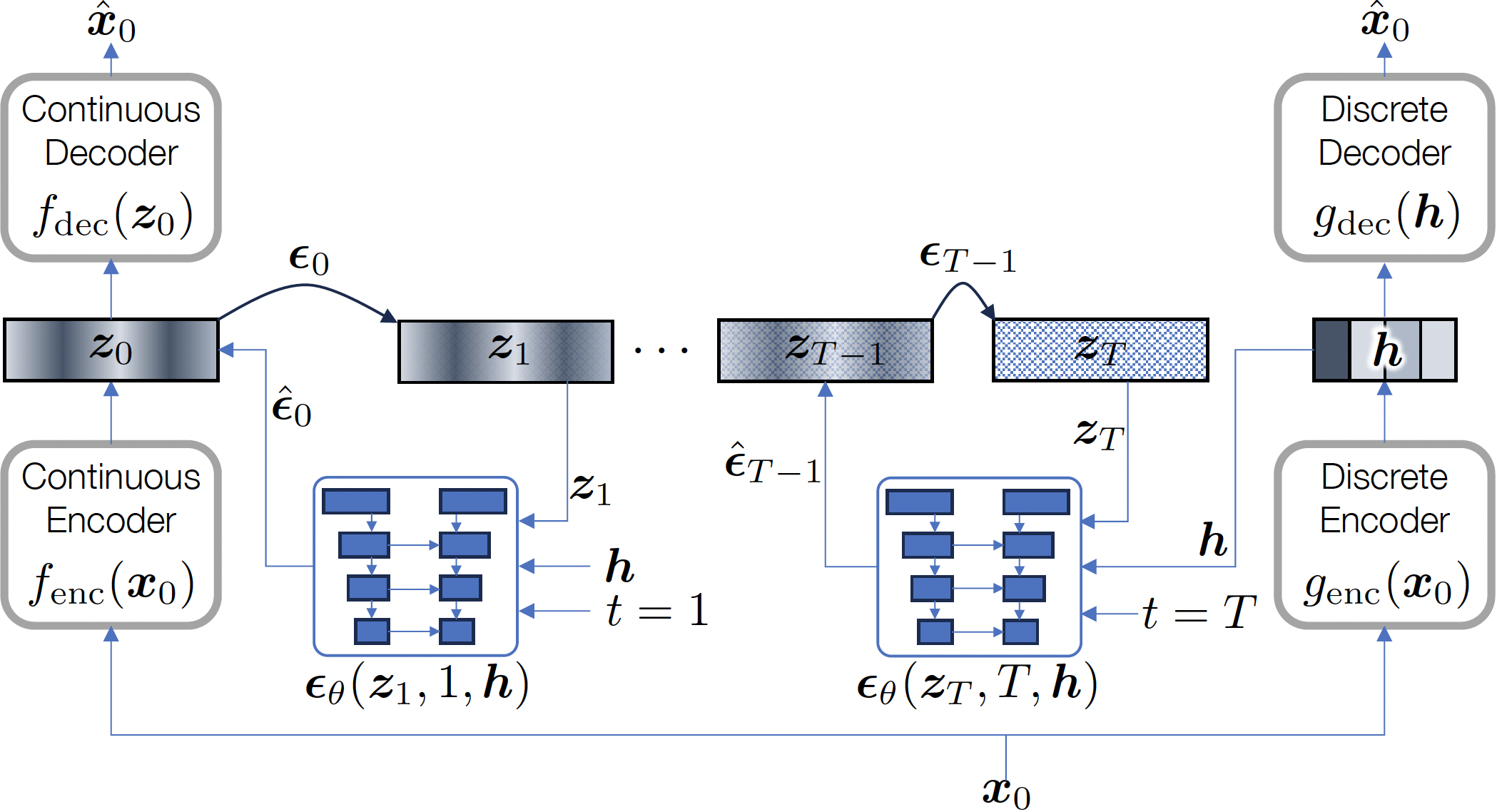
In low-bitrate speech coding, end-to-end speech coding networks aim to learn compact yet expressive features and a powerful decoder in a single network. A challenging problem as such results in unwelcome complexity increase and inferior speech quality. In this paper, we propose to separate the representation learning and information reconstruction tasks. We leverage an end-to-end codec for learning low-dimensional discrete tokens and employ a latent diffusion model to de-quantize coded features into a high-dimensional continuous space, relieving the decoder's burden of de-quantizing and upsampling. To mitigate the issue of over-smooth generation, we introduce midway-infilling with less noise reduction and stronger conditioning.
Audio Coding & Generative Model
Neural Feature Predictor for Low-Bitrate Speech Coding
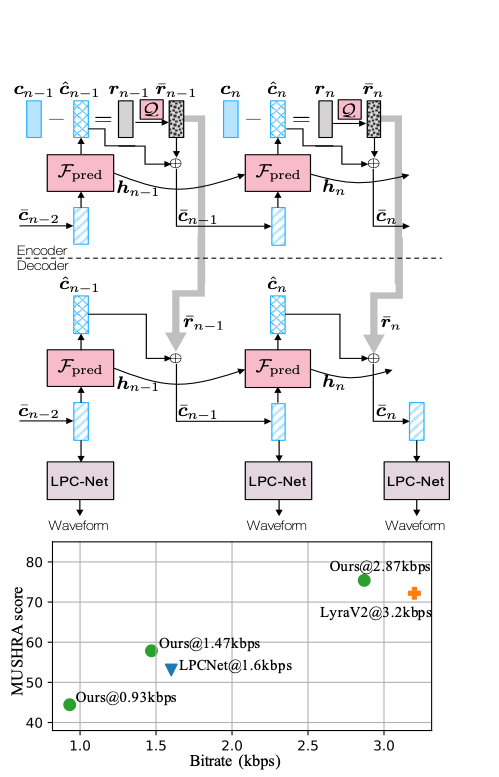
Low and ultra-low-bitrate neural speech coding achieves unprecedented coding gain by generating speech signals from compact speech features. This paper introduces additional coding efficiency by reducing the temporal redundancy within the frame-level feature sequence. We leverage a recurrent neural predictor, which leads to low-entropy residual representations. Residual representations are discriminatively coded according to their contributions to reconstructing signals. Combining feature prediction and discriminative coding results in a dynamic bit-allocating algorithm that spends more bits on unpredictable but rare events. As a result, we develop a scalable, lightweight, low-latency, and low-bitrate neural speech coding system. The subjective tests show that our model achieves superior coding efficiency compared to LPCNet and Lyra V2 in the very low bitrates.
Audio Coding & Source Separation
Source-Aware Neural Audio Coding (SANAC)
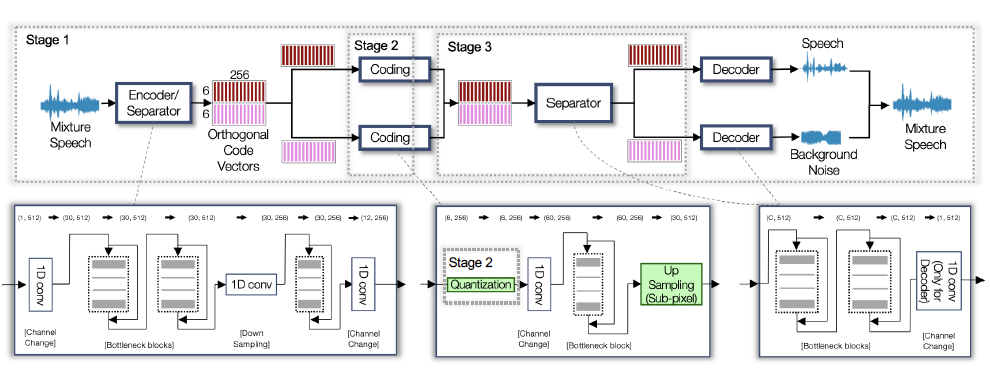
The intuition of the coding problem is to target the use case where source speech is observed as a mixture with background sound. It is to address the common situations, where people would like to know the environmental status of the speaker, even though they still pay the most attention to the speech content. We harmonized the source separation concept into the coding system, so that its encoder predicts the speech and noise code vectors defined in their own latent spaces
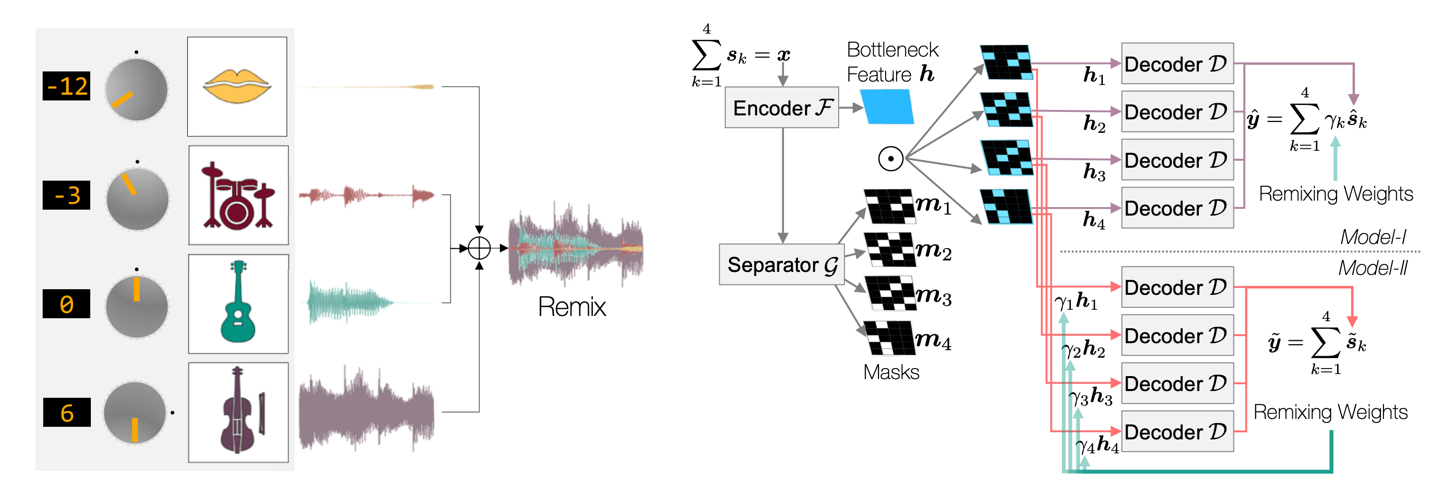
Don't Separate, Learn to Remix: End-to-end Neural Remixing with Joint Optimization
The task of manipulating the level and/or effects of individual instruments to recompose a mixture of recordings, or remixing, is common across a variety of applications. This process, however, traditionally requires access to individual source recordings, restricting the creative process. Source separation algorithms can separate a mixture into its respective components, which a user can adjust the levels and mix them back together. This two-step approach, however, still suffers from audible artifacts and motivates further work. In this work, we learn to remix music directly by re-purposing Conv-TasNet, a well-known source separation model, into two neural remixing architectures. We explicit a loss term that directly measures remix quality and jointly optimize it with a separation loss.
Generative Model & Audio Upmixing
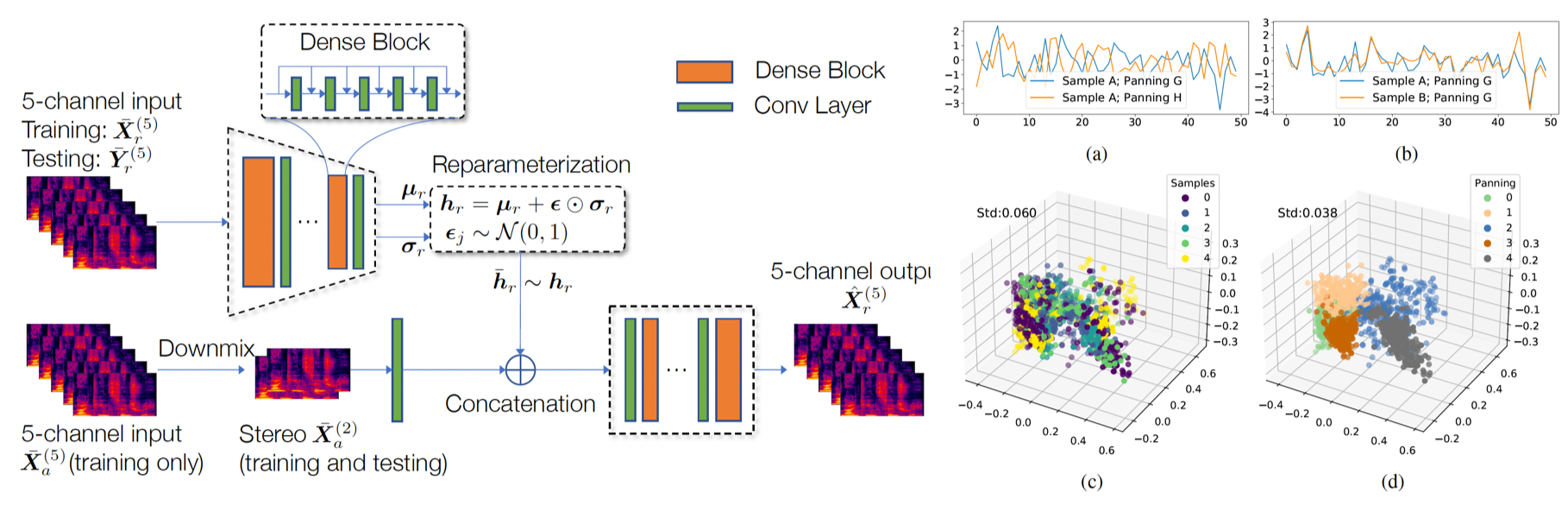
Upmixing via Style Transfer: A Variational Autoencoder for Disentangling Spatial Images and Musical Content
In the stereo-to-multichannel upmixing problem for music, one of the main tasks is to set the directionality of the instrument sources in the multichannel rendering results. In this paper, we propose a modified variational autoencoder model that learns a latent space to describe the spatial images in multichannel music. We seek to disentangle the spatial images and music content, so the learned latent variables are invariant to the music.
Non-local Convolutional Neural Network for Speaker Recognition
In the past few years, various convolutional neural network (CNN) based speaker recognition algorithms have been proposed and achieved satisfactory performance. However, convolutional operations are building blocks that typically perform on a local neighborhood at a time and thus miss to capturing global, long-range interactions at the feature level which are critical for understanding the pattern in a speaker’s voice. In this work, we propose to apply Non-local Convolutional Neural Networks (NLCNN) to improve the capability of capturing long-range dependencies at the feature level, therefore improving speaker recognition performance.
Previous Projects in Digital Humanities
Visualization & NLP
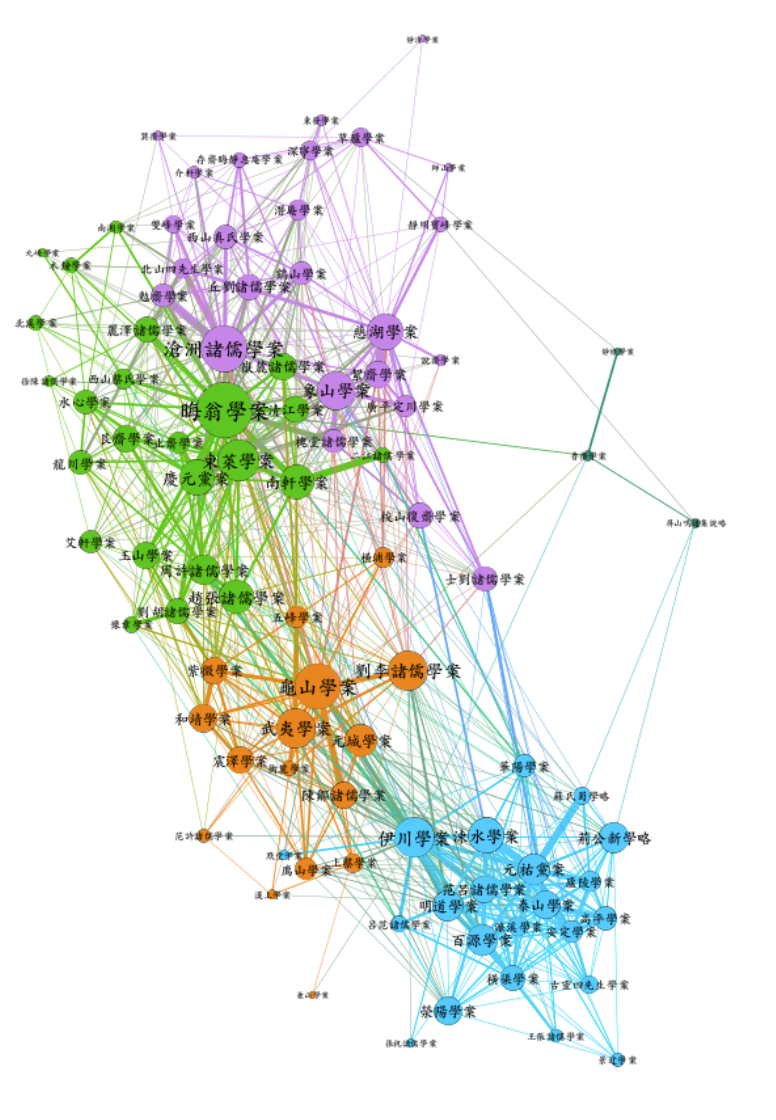
Text Mining and Distant Reading on SongYuanXueAn
This is a digital humanity project. Network analysis and word embedding was conducted on the text data extracted from an ancient chinese book - SongYuanXueAn.
Visualization & Knowledge Graph
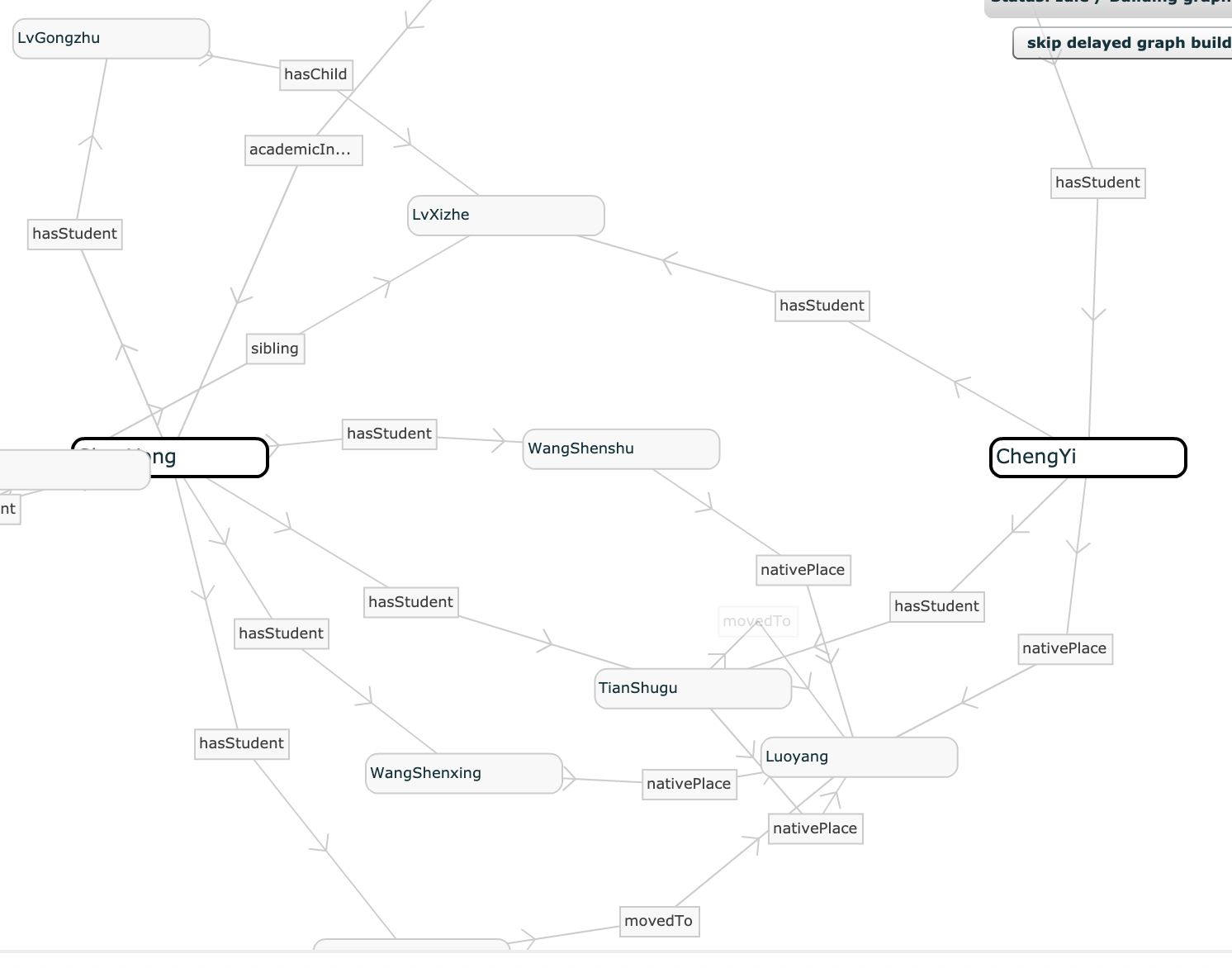
Knowledge Graph Construction of People In Song Dynasty
I built a knowledge graph based on data from CBDB dataset. Feel free to explore scholars and politicians' social network in China a thousand years ago (from AC 900 to AC 1200) by clicking here.
[Demo]